Multi-Node Multi-GPU Datalog
Multi-Node Multi-GPU Datalog
Shovon, A. R., Sun, Y., Micinski, K., Gilray, T., Kumar, S.
- Location: Salt Lake City, Utah
- Link: https://doi.org/10.1145/3721145.3730431
- PDF: ashovon_ics2025.pdf
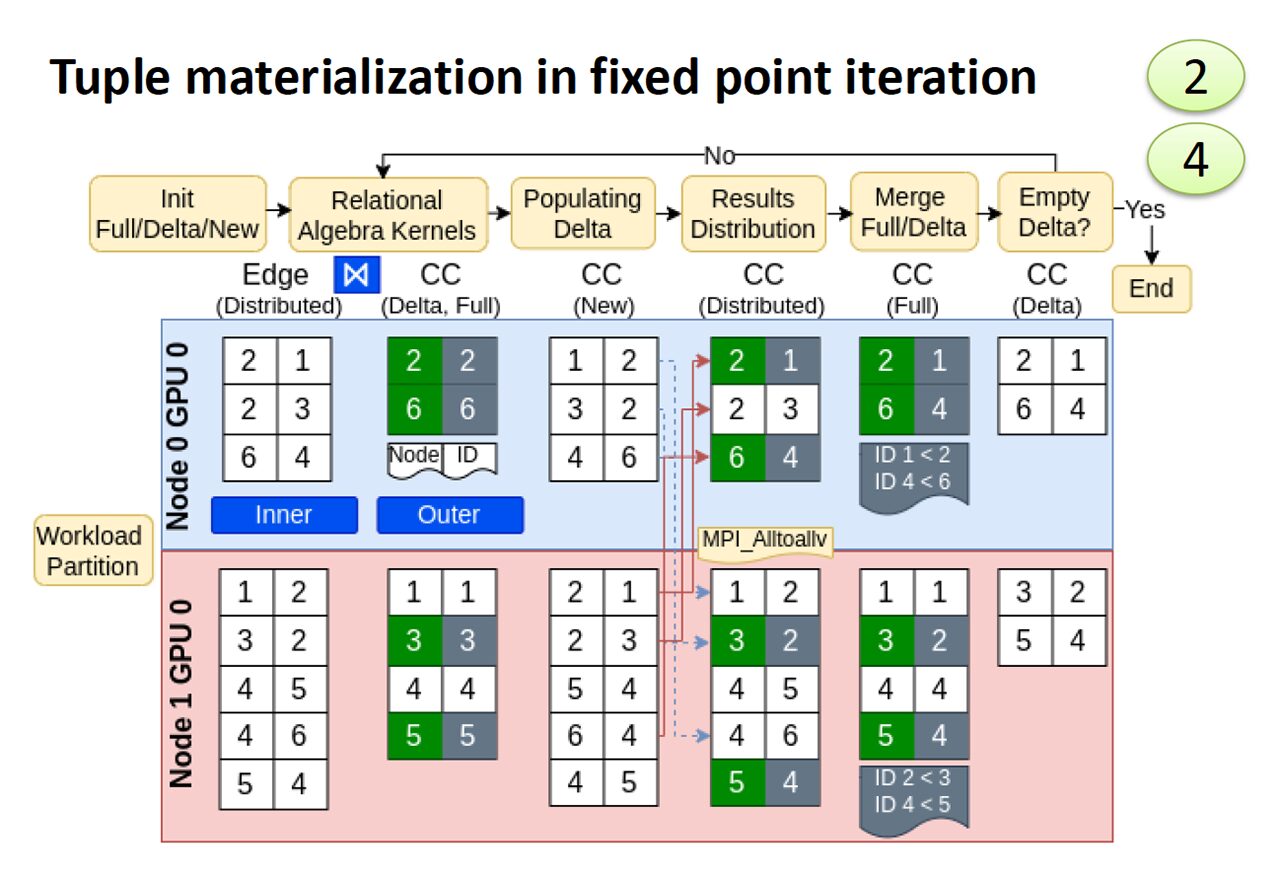
- Caption: First iteration of semi-naïve evaluation with local aggregation on Weakly Connected Component (WCC) query using mnmgDatalog.
Datalog, a declarative logic programming language that operates bottom-up, has experienced increasing popularity due to its natural handling of recursive queries. Its applications span diverse fields, including graph mining, program analysis, deductive databases, and neuro-symbolic reasoning. While Datalog shares similarities with SQL in using relational algebra kernels, it uniquely employs iterative execution until reaching a fixed point to support recursion. Current Datalog engines like SLOG, LogicBlox, and Soufflé work well with multi-core and multi-threaded systems, but none have yet tackled multi-node, multi-GPU architectures. Our research addresses this gap by developing the first multi-GPU, multinode Datalog engine. This advancement is particularly for high-performance computing (HPC) systems, which typically feature multiple GPUs per node. Our implementation combines MPI for inter-node communication with CUDA for GPU parallelization, enabling the processing of massive datasets in real time. We have created novel data-parallel implementations of core relational algebra operations (join), while also optimizing deduplication and tuple materialization. To handle iterative execution, we have developed two novel GPU-accelerated methods for non-uniform all-to-all data exchange. Evaluating on Argonne National Lab’s Polaris supercomputer demonstrated our engine’s effectiveness, achieving performance improvements of up to 32× against state-of-the-art multi-node Datalog engine.
Keywords: Datalog, Multi-GPU, Analytic Databases
https://doi.org/10.1145/3721145.3730431